この度、マルチモーダル画像融合分野において、本学部の科学研究チームの新たな研究成果が人工知能とコンピュータビジョン分野のトップジャーナルであるInternational Journal of Computer Vision (IJCV)に収録された。劉晋源博士、林潤甲修士大学院生、呉冠尭修士大学院生、劉日昇教授、羅鐘鉉教授と樊鑫教授(責任著者)が協力して、研究成果CoCoNet: Coupled Contrastive Learning Network with Multi-level Feature Ensemble for Multi-modality Image Fusionを完成させた。これは幾何学計算とインテリジェントメディア技術研究所チームのこの分野における最新の研究成果だ。
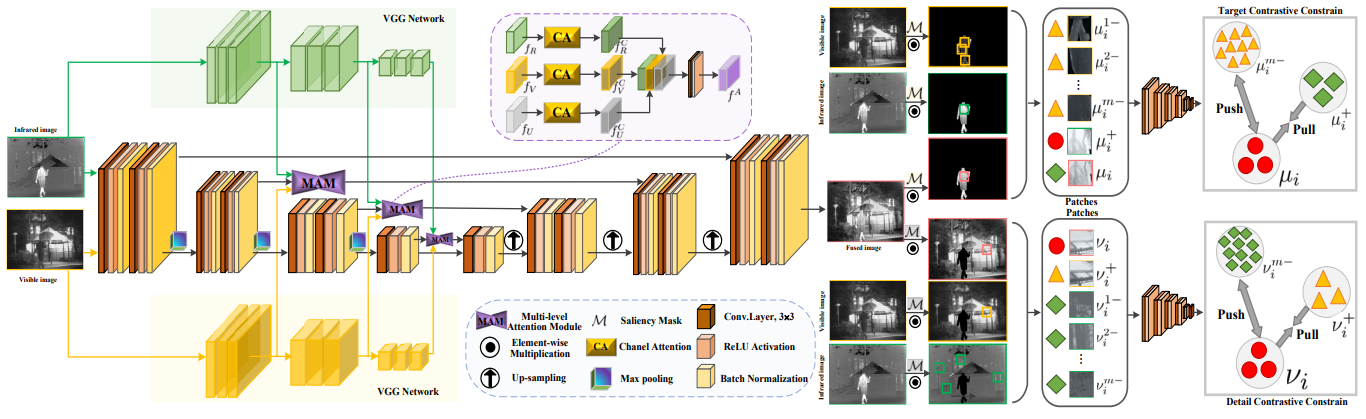
マルチモーダル画像融合は、異なるセンサーから得られる補完的な情報を統合することにより、情報の量と質を大幅に向上させる融合画像を取得するが、これは、視覚を強化し、画像意味分析アプリケーションを改善する上で重要な意義がある。チームは、既存の深層学習マルチモーダル画像融合アルゴリズムには、主にさまざまな損失関数を構築することで相補的な特徴を保存するが、通常は異なるセンシングモダリティ間の内在的な接続を無視し、その結果、融合結果に冗長または無効な情報が生じるという問題があることを発見した。この問題を解決するために、本論文では、融合画像の前景ターゲット/背景の詳細と、対応する赤外/可視光源画像が特徴表現空間で密接に接続され、別のモダリティの特徴から遠く離れるように、損失関数を最適化するための結合コントラスト制約を革新的に提案し、融合プロセスにおける歪み現象を効果的に回避した。さらに、本論文では、豊富な階層的特徴表現を学習し、融合プロセス中に意味情報特徴を包括的に伝送するためのマルチレベルアテンションモジュールを導入することで、複数の画像融合タスクとそれに続く意味知覚タスクで促進作用を実現した。関連成果は https://github.com/runjia0124/CoCoNet にオープンソース化されている。

